-
Type:
Story
-
Status: Closed (View Workflow)
-
Resolution: Done
-
Affects Version/s: None
-
Fix Version/s: None
-
Component/s: None
-
Labels:None
-
Sprint:2022.R4 New Features Sprint 1
-
SCRUM Team:Brotherhood of Mutants
-
Story Points:5
-
Work Type Classification:Sustaining
We will need a story to research about the Rebank functionality what it is.
here is the original ticket for this : https://jira.hotschedules.com/browse/CFAMX-19754
here are the goals:
we should understand what Rebank Type is.
Do we need it?
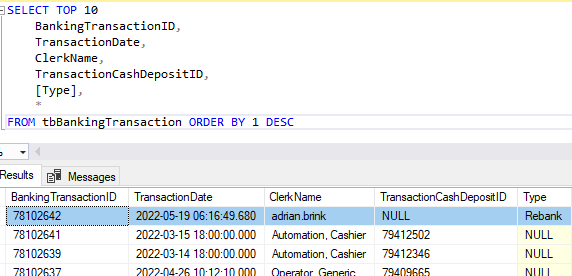
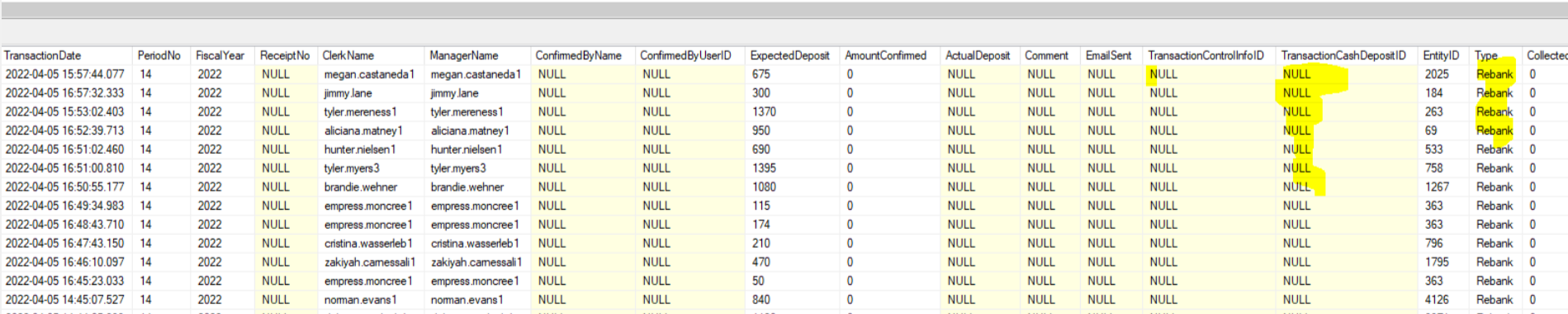
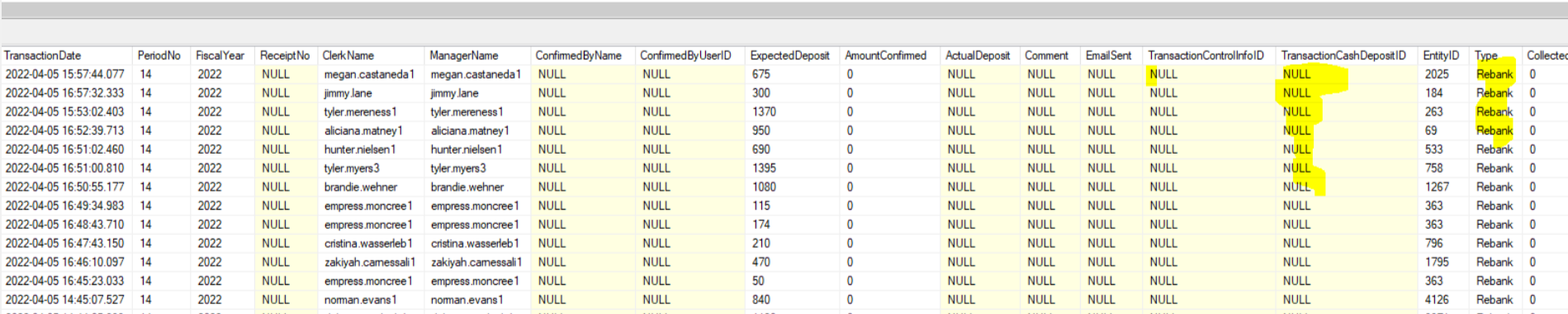
Why it is inserting TransactionCashDepositId as nulls?
select top 20 * from tbBankingTransaction with (nolock) where transactioncashdepositid is null
order by 1 desc
If this functionality is needed and and we cant provide a valid unique TransactionCashDepositId then we should look for the other possible options like splitting table Rebank type transactions to another table?
the goal here is to prevent duplicated transactioncashdepositid records without having tablelockx.
just some notes from the original ticket
"We have done the best implementation we could at the moment by implementing tablelocx on tbBankingTransaction table to prevent duplicates. This fix is fine if we have optimal CPU usage. In case it goes high like %80 we may see this error occur again.
Another option could be is adding a unique constraint on tbBankingTransaction but according to our research this can not be done because transactioncashdepositId column is empty for rebank records. If Rebank functionality is not in use we can start thinking going with this route as well. We are investigating this."
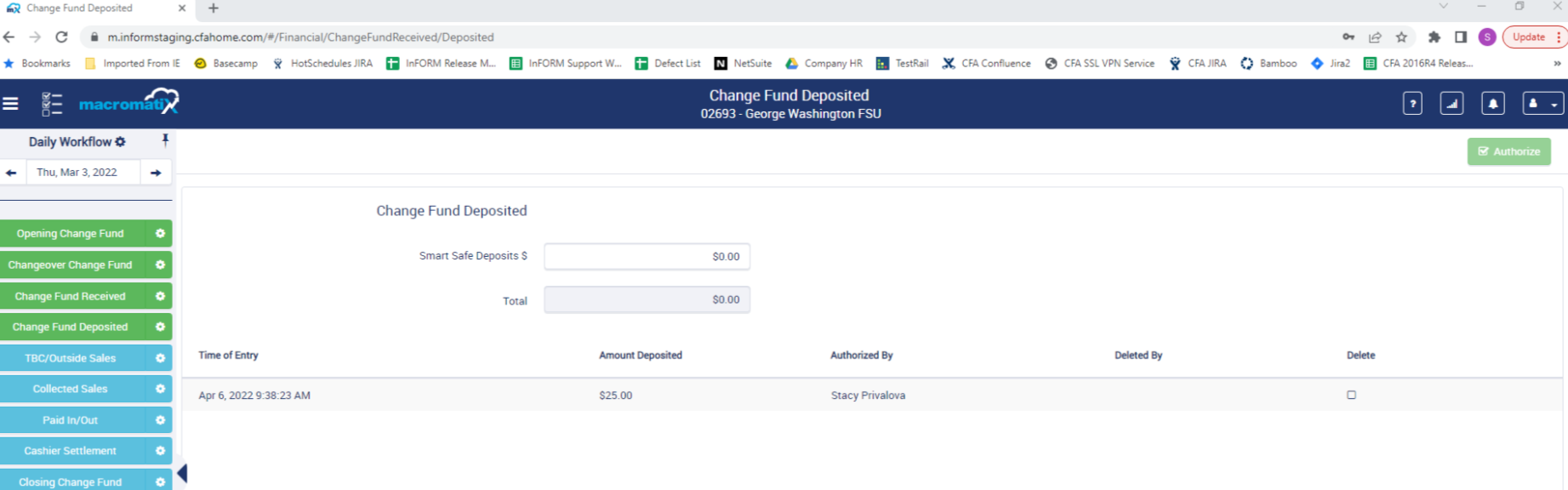
*Here is what Stacy says about this : *
Rebank record is populated by Change Fund Deposited task
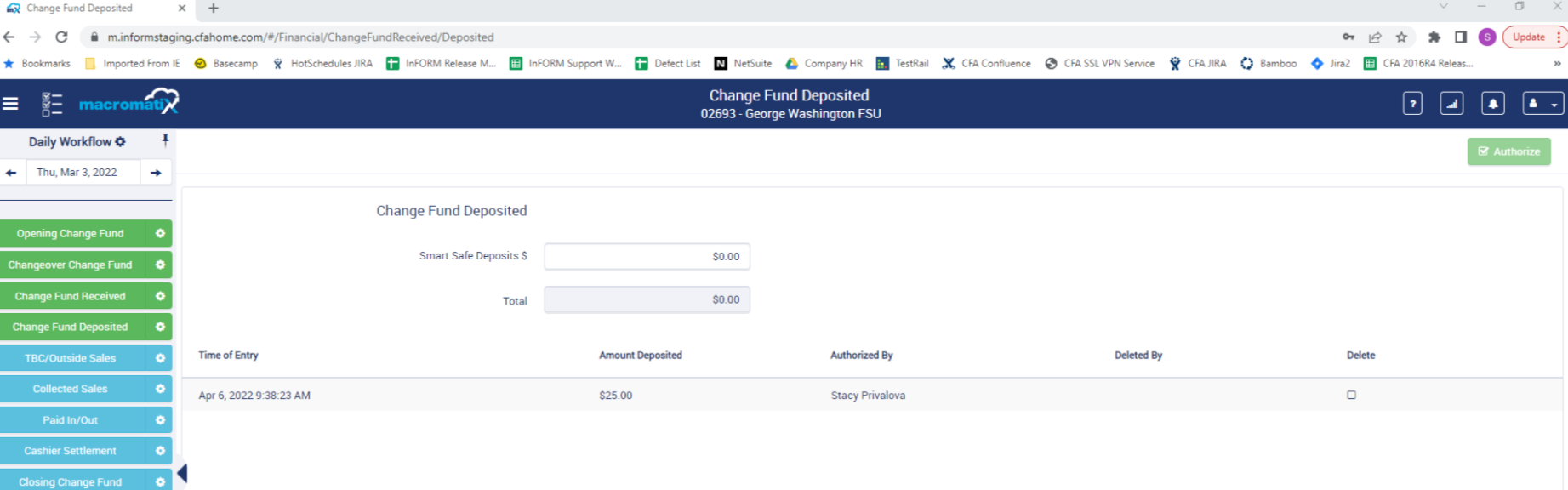
SELECT ExpectedDeposit, ReceiptNo, * FROM tbBankingTransaction with (nolock)
where
EntityID = 1810
and BusinessDay >= '2022-02-01'
and type = 'Rebank'